더티 데이터란?
더티 데이터(Dirty Data)는 불완전하거나 부정확한 데이터를 의미하며, 분석에 활용하기 위해서는 반드시 정제 과정이 필요합니다. 더티 데이터는 여러 가지 형태로 나타날 수 있는데, 아래 예시를 통해 각각의 사례를 구체적으로 살펴보겠습니다.
예시: 고객 정보 데이터셋
| 고객 ID | 이름 | 나이 | 가입 날짜 | 구매 금액 | 성별 | 이메일 |
| 001 | 김철수 | 28 | 2021-08-15 | 500,000 | 남성 | chulsoo@gmail.com |
| 002 | 이영희 | 25 | 2022/01/12 | 오십만원 | 여성 | yeonghee.com |
| 003 | 박민수 | 2022-05-20 | 1,200,000 | 남성 | minsoo@gmail.com | |
| 004 | 강호동 | 40 | 2015-13-20 | 300,000 | 남성 | hodong@gmail.com |
| 005 | 손예진 | -30 | 2023-03-01 | 2000000000 | 여성 | yejin@gmail.com |
| 002 | 이영희 | 25 | 2022-01-12 | 50,0000 | 여성 | yeonghee.com |
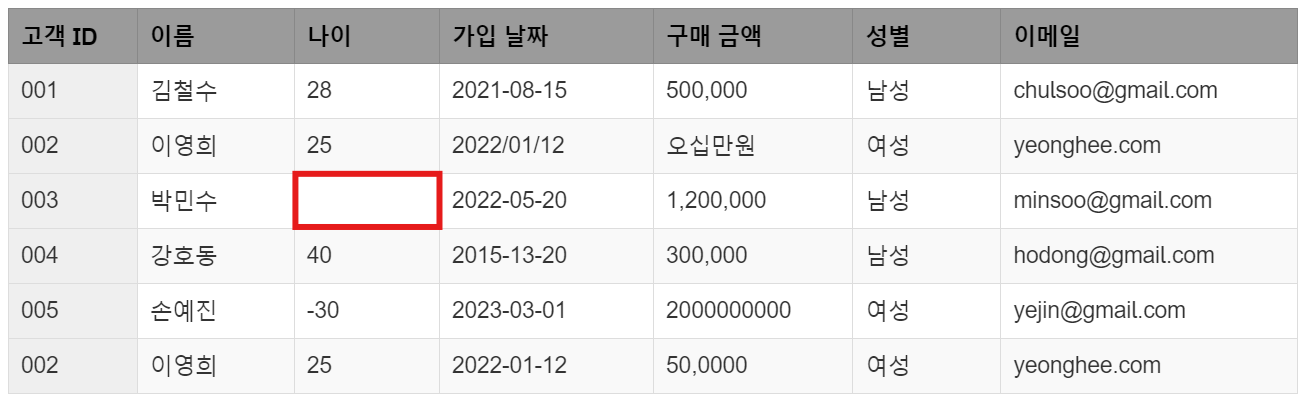
1. 누락된 값(Missing Data)
박민수(003번 고객)의 나이 데이터가 입력되지 않았습니다. 고객의 나이 정보는 분석 시 매우 중요한 변수일 수 있습니다. 나이가 없으면 나이대별 분석이나 특정 연령층을 대상으로 하는 마케팅 전략 수립에 방해가 됩니다.
이러한 누락된 값은 여러 방법으로 처리할 수 있습니다. 예를 들어, 전체 고객의 평균 나이를 넣거나 비슷한 다른 고객의 데이터를 바탕으로 예측값을 채울 수 있습니다. 또한, 경우에 따라 이 데이터를 제외할 수도 있습니다.
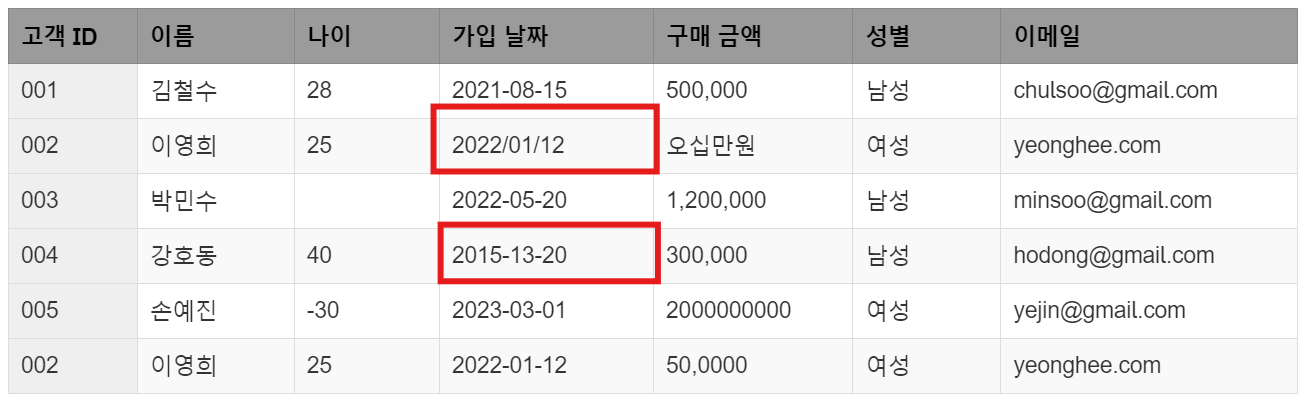
2. 잘못된 형식(Incorrect Formatting)
이영희(002번 고객)의 가입 날짜가 2022/01/12로 다른 고객의 YYYY-MM-DD 형식과 다르게 입력되어 있습니다. 날짜 형식의 불일치는 시간 기반 분석이나 정렬에 문제를 일으킬 수 있습니다. 또한 강호동(004번 고객)의 가입 날짜가 2015-13-20으로 입력되었는데, 13월은 존재하지 않는 날짜입니다. 이런 경우, 날짜 형식을 일관되게 맞추고 비현실적인 날짜를 수정하는 작업이 필요합니다.
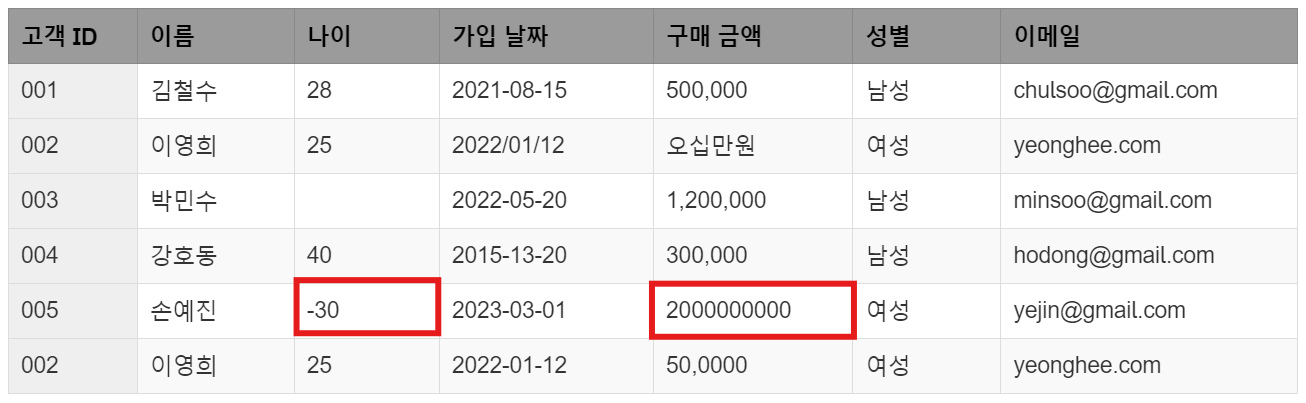
3. 비현실적 값 및 이상치(Outliers and Unrealistic Data)
손예진(005번 고객)의 나이는 -30으로 입력되어 있습니다. 나이가 음수가 될 수 없으므로 이는 명백한 입력 오류입니다. 또한 손예진 고객의 구매 금액이 2,000,000,000원으로, 다른 고객들에 비해 비현실적으로 높습니다. 이러한 비정상적인 값은 분석 결과를 왜곡할 수 있습니다. 따라서, 나이 데이터를 올바르게 수정하거나 구매 금액이 이상치인지 확인한 후 처리해야 합니다. 특정 범위를 초과하는 값들은 분석에서 제외하거나 적절한 상한선/하한선을 설정해 처리합니다.
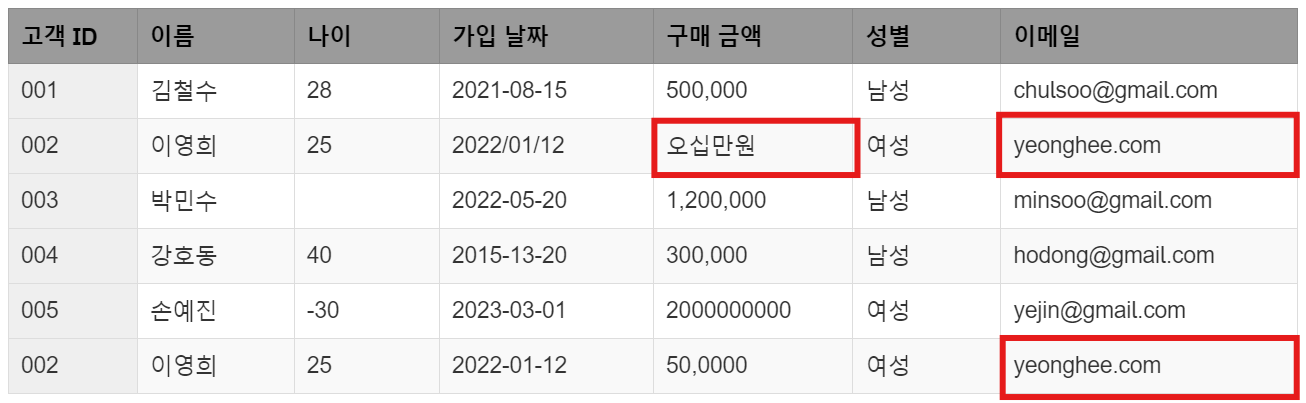
4. 중복 데이터(Duplicate Data)
이영희(002번 고객)의 정보가 두 번 기록되었습니다. 고객 ID와 다른 정보들이 동일하게 중복되어 있어, 중복된 데이터는 분석 과정에서 동일한 고객이 여러 번 계산될 위험이 있습니다. 이는 매출, 고객 수 등 통계적인 결과에 부정적인 영향을 미칩니다.

5. 잘못된 레이블링(Mislabeling)
이영희(002번 고객)의 구매 금액이 '오십만원'이라는 한글로 입력되어 있습니다. 다른 고객들의 구매 금액은 숫자로 입력되어 있지만, 이 경우는 텍스트로 입력되어 있어 분석 시 텍스트를 숫자로 변환해야 하는 추가 작업이 필요합니다. 또한, 이영희의 이메일 주소는 @가 누락되어 있습니다. 이메일 주소 형식이 잘못되면 해당 고객과 연락하는 데 문제가 발생할 수 있습니다.
이처럼 더티 데이터는 여러 가지 문제를 야기할 수 있으며, 이를 정제하지 않으면 분석의 신뢰성이 떨어집니다. 따라서 더티 데이터는 분석에 앞서 반드시 수정 및 정제가 필요합니다.
'공부 > 데이터' 카테고리의 다른 글
| 공개 데이터를 볼 수 있는 사이트 총 정리 (0) | 2023.12.05 |
|---|---|
| 지도학습(Supervised Learning) 알고리즘 이해와 주요 알고리즘 정리 (0) | 2023.12.04 |
| 오픈 데이터를 제공하는 사이트 정리 (0) | 2023.12.04 |
| 머신러닝의 분류: 지도학습/비지도학습/강화학습 (0) | 2023.12.02 |
| 손실함수의 이해와 종류/파이썬으로 구현까지 (0) | 2023.12.01 |